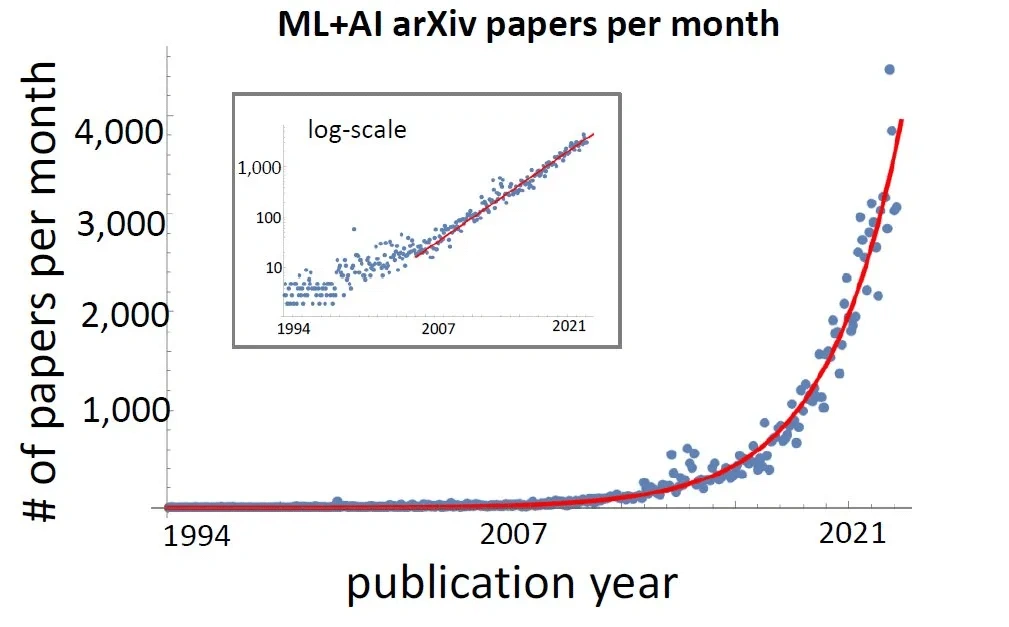
如果你觉得最近 AI 生成内容似乎又是一个「风口」,那么你并不孤独。因为在 arXiv 上,关于机器学习 + AI 相关的论文发布趋势呈指数级上升 —— 你根本没有时间来啃下那么多的论文,然后新的应用就出来了。
据几位投资人朋友说,国内拿到投资的在做 AI 生成图片社区的、各种开源算法改造的团队有几十家之多;身边的朋友也开始逐渐找我讨论有没有什么新的机会。
在喧闹声中,作为 Open AI 的创始成员,现任特斯拉人工智能高级总监, Andrej Karpathy 的这篇文章中的思考反而能让我们冷静下来。
在本文中,他通过完成下面几件事,来通过历史预测未来的发展
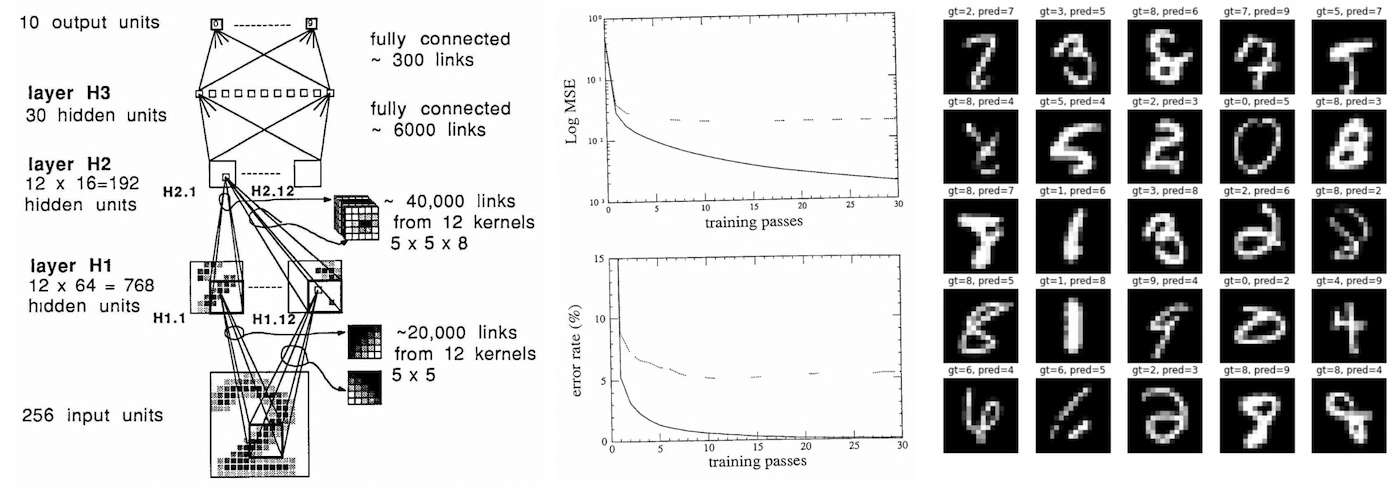
复原最早关于端到端的神经网络训练论文,1989 年 Yann LeCun 等人撰写的,基于反向传播的手写邮政编码识别 应用。当时的数据集仅有 7291 个,以及 1000 个神经元,用最当时最先进的服务器训练了三天,错误率为 4.09% ;
用今日的方法改造模型,增大数据集,发现错误率降低到了 1.25%,并且训练时间仅仅花费了M1 Mac 的 30 秒时间。
通过尽可能忠实地还原当时推导的过程,并用今天的技术,公平地改进它(从数据集到模型),然后利用这个事实推演未来的情况。
通过对论文的还原,Karpathy 的一些思考总结如下:
{kind=link}
{kind=link}